特徵选择/范例五: Test with permutations the significance of a classification score
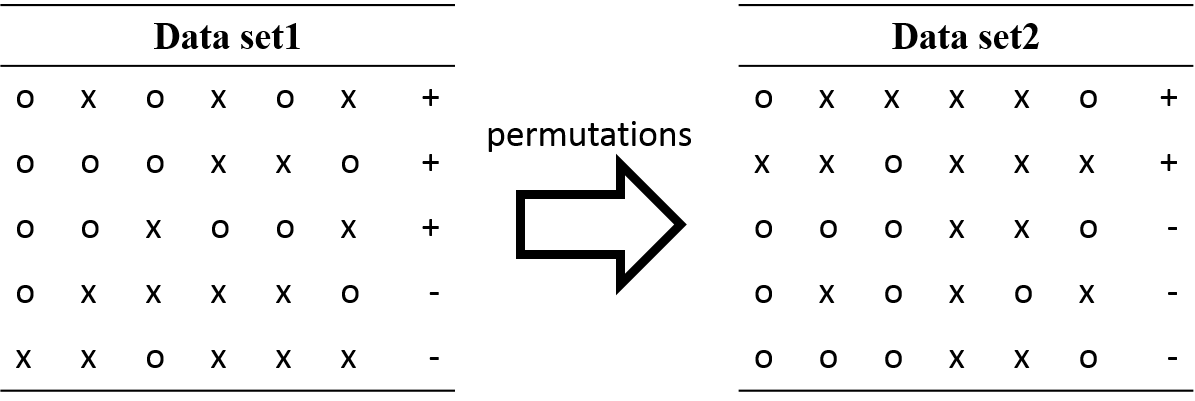
此范例主要是用于当我们做机器学习分类时,资料标籤为无大小关系的分类,也就是第一类与第二类并无前后大小关系的分类。由于输入分类器的标籤仍为数值,但数值的大小可能影响分类结果,因此随机置换分类标籤以及随机的训练测试资料组(交叉验证)来输入分类机,针对不同类型的分类做对应的评分,统计出不同的资料与标籤组合所得到的准确度与标籤的显著性。
permutation_test_score提供了对分类标籤做随机置换的功能,并依照给定的置换次数来计算不同的资料组合配上置换过标籤的组合,用交叉验证来计算准确性分佈,并统计显著性。计算过后可取得该分类机器的真实分数与经过数次组合后取得的分数。
- 资料集:鸢尾花
- 特徵:萼片(sepal)之长与宽以及花瓣(petal)之长与宽
- 预测目标:共有三种鸢尾花 setosa, versicolor, virginica
- 机器学习方法:线性分类
- 探讨重点:变换训练资料分类的目标标籤,减少标籤数值对分类的影响
- 关键函式:
sklearn.cross_validation.permutation_test_score
【1】Ojala and Garriga. Permutation Tests for Studying Classifier Performance. The Journal of Machine Learning Research (2010) vol. 11
(一)取得鸢尾花资料
本范例使用datasets.load_iris()读取具有4个资讯影响力特徵与150个样本的鸢尾花资料,该资料被分类为三个类型。并且额外增加2200笔150长度的杂讯做为不具资讯影响力的特徵,来增加辨认複杂度。
# Loading a dataset
iris = datasets.load_iris()
X = iris.data
y = iris.target
n_classes = np.unique(y).size
# Some noisy data not correlated
random = np.random.RandomState(seed=0)
E = random.normal(size=(len(X), 2200))
# Add noisy data to the informative features for make the task harder
X = np.c_[X, E]
(二)建立基本的支持向量分类机
使用SVC建立最基本的支持向量分类机。并设定训练交叉验证的摺叠系数为2。
svm = SVC(kernel='linear')
cv = StratifiedKFold(y, 2)
(三)重複随机变换训练资料并统计准确率
当整理好训练资料,以及支持向量分类机的设定后,我们以permutation_test_score功能来测试不同的随机训练资料组合,以及对应的分类机分数。除了基本的支持向量机物件、训练资料、训练目标,还需要指定对分类结果的评分方式、交叉验证物件。与重複随机变换法有关的参数像是置换次数(预设为100)与使用CPU的数目(预设为1)也可依照使用者使用情况而改变。
score, permutation_scores, pvalue = permutation_test_score(
svm, X, y, scoring="accuracy", cv=cv, n_permutations=100, n_jobs=1)
print("Classification score %s (pvalue : %s)" % (score, pvalue))
经过计算的结果,会给予实际的分类机分数、每次随机置换的分数以及p-value。
(四)统计随机置换资料算出来的分类机分数图表
最后一个部分,就是把permutation_test_score算出来的结果以图表的方式呈现。
###############################################################################
# View histogram of permutation scores
plt.hist(permutation_scores, 20, label='Permutation scores')
ylim = plt.ylim()
# BUG: vlines(..., linestyle='--') fails on older versions of matplotlib
#plt.vlines(score, ylim[0], ylim[1], linestyle='--',
# color='g', linewidth=3, label='Classification Score'
# ' (pvalue %s)' % pvalue)
#plt.vlines(1.0 / n_classes, ylim[0], ylim[1], linestyle='--',
# color='k', linewidth=3, label='Luck')
plt.plot(2 * [score], ylim, '--g', linewidth=3,
label='Classification Score'
' (pvalue %s)' % pvalue)
plt.plot(2 * [1. / n_classes], ylim, '--k', linewidth=3, label='Luck')
plt.ylim(ylim)
plt.legend()
plt.xlabel('Score')
plt.show()

原始码出处
Python source code: plot_select_from_model_boston.py
# Author: Alexandre Gramfort <alexandre.gramfort@inria.fr>
# License: BSD 3 clause
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.cross_validation import StratifiedKFold, permutation_test_score
from sklearn import datasets
##############################################################################
# Loading a dataset
iris = datasets.load_iris()
X = iris.data
y = iris.target
n_classes = np.unique(y).size
# Some noisy data not correlated
random = np.random.RandomState(seed=0)
E = random.normal(size=(len(X), 2200))
# Add noisy data to the informative features for make the task harder
X = np.c_[X, E]
svm = SVC(kernel='linear')
cv = StratifiedKFold(y, 2)
score, permutation_scores, pvalue = permutation_test_score(
svm, X, y, scoring="accuracy", cv=cv, n_permutations=100, n_jobs=1)
print("Classification score %s (pvalue : %s)" % (score, pvalue))
###############################################################################
# View histogram of permutation scores
plt.hist(permutation_scores, 20, label='Permutation scores')
ylim = plt.ylim()
# BUG: vlines(..., linestyle='--') fails on older versions of matplotlib
#plt.vlines(score, ylim[0], ylim[1], linestyle='--',
# color='g', linewidth=3, label='Classification Score'
# ' (pvalue %s)' % pvalue)
#plt.vlines(1.0 / n_classes, ylim[0], ylim[1], linestyle='--',
# color='k', linewidth=3, label='Luck')
plt.plot(2 * [score], ylim, '--g', linewidth=3,
label='Classification Score'
' (pvalue %s)' % pvalue)
plt.plot(2 * [1. / n_classes], ylim, '--k', linewidth=3, label='Luck')
plt.ylim(ylim)
plt.legend()
plt.xlabel('Score')
plt.show()