Feature Selection
特徵选择 特徵选择主要是以统计特徵与目标的相关性、或以叠代排序特徵影响目标影响力的方式来逐渐排除与目标较不相关的特徵,留下与目标最相近的特徵,使判断准确率能够提升。
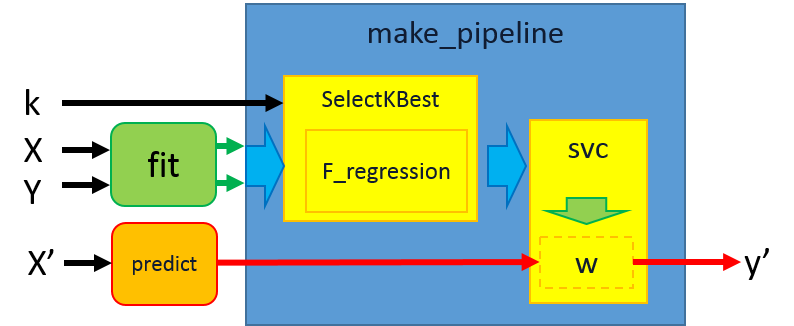
范例一:Pipeline Anova SVM
以anova filter作为选择特徵的依据,并示范以传递(Pipeline)的方式来执行特徵选择的训练。
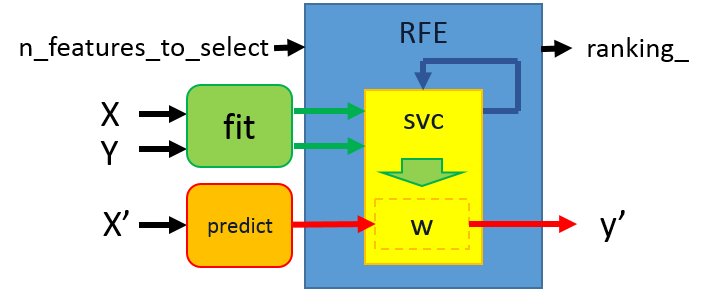
范例二:Recursive feature elimination
以重複排除最不具有特徵影响力的特徵,来减少训练的特徵数目,直到指定的特徵数目。
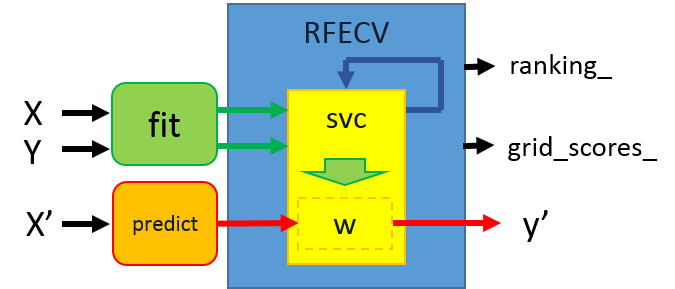
范例三:Recursive feature elimination with cross-validation
除了重複排除不具影响力的特徵外,对每次排除特徵后计算准确度,以准确度最高的特徵数目作为选定训练特徵数目的依据。
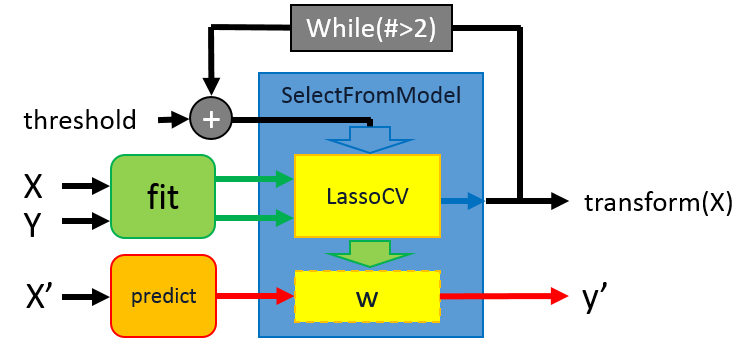
范例四:Feature selection using SelectFromModel and LassoCV
示范如何使用SelectFromModel函式来选择给定的函式,并设置输入函式的门槛值,用以判断训练的特徵数目。在本范例是使用LassoCV作为选择的涵式。
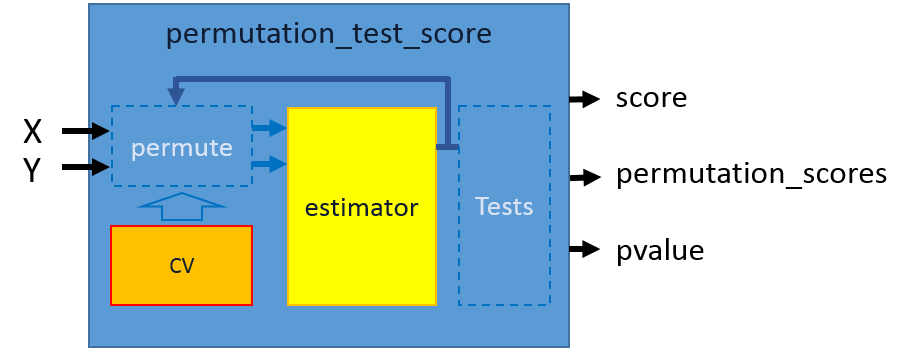
范例五:Test with permutations the significance of a classification score
本范例示范当目标类型的特徵,并无数值的大小区分时,以置换分类目标的方式来找到最高准确率的特徵挑选结果。以避免因为特徵目标分类转换为用以区分不同类型时造成的误判。
范例六:Univariate Feature Selection
本范例示范用SelectPercentile以统计的方式来做特徵的选择,并比指定的判断函式来挑选特徵。本范例的输入涵式为ANOVA,并以计算的F-value来做为挑选特徵的判断。